【Rust学习记录】4. 所有权
所有权和生命周期据说是Rust最难学也最核心的两个概念,也是Rust在没有垃圾回收的机制下确保内存安全的秘诀,现在就能开始接触这第一咯核心概念了。
什么是所有权
前言
一般内存管理就两种:1. 自动垃圾回收:在运行的时候定期检查并回收没有使用的内存;2. 程序员手动分配和释放;Rust提出了第三种规则,这套规则目的在于能让编译器在编译的过程中就检查内存问题,不需要在运行的时候花费代价去回收垃圾。
补充概念:
- 栈:后进先出的内存分配结构,没有办法在中间插入存放数据,所以存放在栈里的数据需要已知且固定大小
- 堆:堆的管理比较松散,你可以在堆里请求一个特定的大小的空间,操作系统就会找到一片足够大的地方,标记为已使用,分配给你,返回你一个指向这片地方的指针,因为是指针,所以也方便再申请一块地方,然后把这两块地方串起来,实现动态大小。但因为多了指针跳转,也要不断的寻找足够大的空间,所以在堆里存取数据会比栈里慢。
一般语言都不需要深入了解这两个概念,但书上说这两个概念和Rust的所有权紧密相关,所以我们暂且先看看。
所有权规则
暂时了解,后续会逐一解释
- 每一个值都有一个对应的变量,作为值的所有者
- 在同一时间内,值有且仅有一个所有者
- 当所有者离开了自己的作用域,它持有的值就会被释放掉
变量作用域
这个和其他语言是一模一样的,不费口舌了。
简单来说就是变量只在作用域里变的有效,保持有效直到离开作用域
String类型——一个例子
String是一个存储在堆上的结构,用这个举例会能更好的说明所有权的作用,这一部分主要注重于所有权的部分,而不是去了解关注String
简单例子
我们定义一个动态可变长的字符串
1 | fn main() { |
对于一个可变长度的String变量而言,内存管理主要分两个步骤
- 让操作系统给 String 分配一个堆空间
- 使用完之后,把内存交还给操作系统
第一步在大多数语言里都是一样的,那就是让程序员去发起请求,也就是定义一个变量。
第二步就不一样了,也就是上面介绍过的,要么定期检查自动回收,要么程序员自己来完成。定期回收吧,开销太大,自己完成吧,实现起来又很困难,一不小心回收晚了——内存泄漏,回收早了——非法变量,重复回收了,也可能有无法预知的后果。
所以 Rust 的解决方案是,在变量离开作用域后,立即释放内存。(其实我看到这里还觉得很普通啊,这不是很正常的操作吗?内存泄漏一般是不小心哪里弄了点跨文件的全局变量,一直被 hold 着不释放导致的吧)
Rust 回收是通过一个叫 drop 的函数进行的,也就是说,在 main 函数执行完后,其实 Rust 在花括号后面偷偷调用了一次 drop 函数。
但是,看一下复杂的例子,就能发现一点不一样的地方了
复杂例子
让我们试着定义两个存放在栈里的变量,两个存放在堆里的String变量
1 | fn main() { |
存放在栈里的变量,很符合正常逻辑,我们会创建一个值5给x,然后把 x 里的值拷贝一份,再给 y ,这样我们就有两个5了,互相修改互不影响。
但堆里的不一样,为了保证效率(之前也说了在堆里存取很浪费效率),Rust 在创建堆变量的时候,会附带一个指针,指向这个堆,就像这样
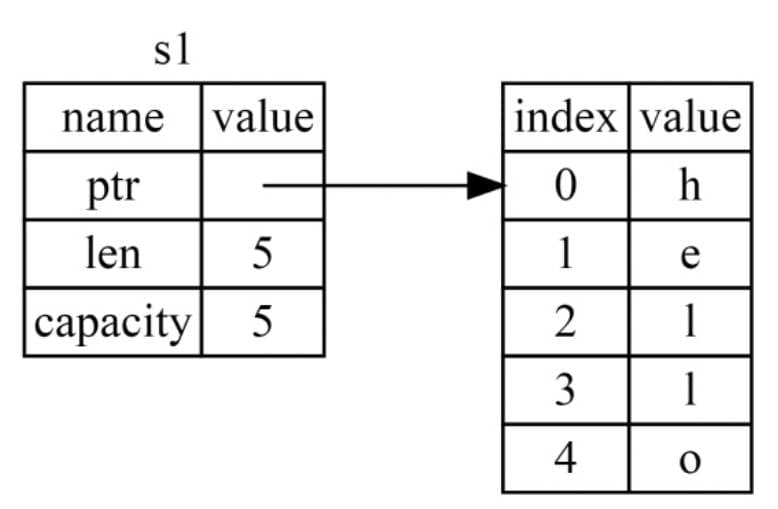
这说明什么,说明我们创建 s2 的时候其实只是拷贝了 s1 的内容,没有拷贝值的内容,只是拷贝了一份新的字段,以及一个新的指针,指向原来的内存块,所以修改的时候,是会相互影响的。好,这一部分也很好理解,毕竟不少语言也是这么干的。
但是!重点来了,之前说过,当重复释放一片内存的时候,可能会造成不可预计的错误,那我们 s2 和 s1 不就在同一个作用域吗,按 Rust 的所有权方法,在离开的时候不就同时释放了这块内存吗?
于是,Rust 用了一个很简单粗暴的方法,解决了这个问题。那就是,当两个变量同时指向了同一块内存的时候,上一个变量就没用了!(此处印证了第一条规则,值有且仅有一个所有者)
你可以尝试一下运行之前的代码,编译器是会报错的,也就是说,在定义了 s2 之后,无法输出 s1 Rust以此来保证没有一块内存是冗余的。奇葩!

报错提示你,你真的要用两个变量名的话,就给编译器说明,你确定是浪费内存,去要克隆一份。
1 | fn main() { |
但也正如上面所说,栈是不受影响的,因为固定长度的变量在栈里操作很快,复制一份也无所谓,所以 x,y 是可以随便用的。
所有权与函数
基于上面的例子,我们就可以发现 Rust 这套规则的作用域,和别的语言完全不同的地方。
1 | fn main() { |
我们可以看一下这段代码,当 s1 被传入函数 string_test 的时候,其实也相当于完成了一次复制,也就是说,把 s1 的值复制给了函数参数 s,导致两者也指向了同一片空间。这代表什么?这段代码编译肯定不会通过,因为 s1 的作用域到执行函数 string_test 就已经结束了!而 x 不会受这个影响。
果然还是大受震撼,让人不禁产生疑问,那要让人怎么随心所欲调用函数了?
同时,函数的返回值也受这个所有权影响,也就是说,当执行返回值的时候,返回值的所有权回到函数上,再交由函数赋予变量上。
针对我提出的疑问,书上马上也给出了回答,如果要让我在调用函数之后保证变量的所有权,那就需要在函数的最后加个返回值,再把所有权返回给我的变量,也就是所用权的变更路线是 s1——参数——返回值——函数——s1
这也太麻烦了,这时候就需要引入另一个概念,让这个操作变得没那么繁琐,那就是——引用。
引用和借用
引用和所有权
既然复制和移动会转移所有权,导致变量有效性消失的问题,那不复制不移动不就完了?这个操作,就需要用到引用。
1 | fn main() { |
这段代码就完全没有问题了。
引用和别的语言概念也一样,应该不需要多说,创建一个新的引用,它的本质是这样的。
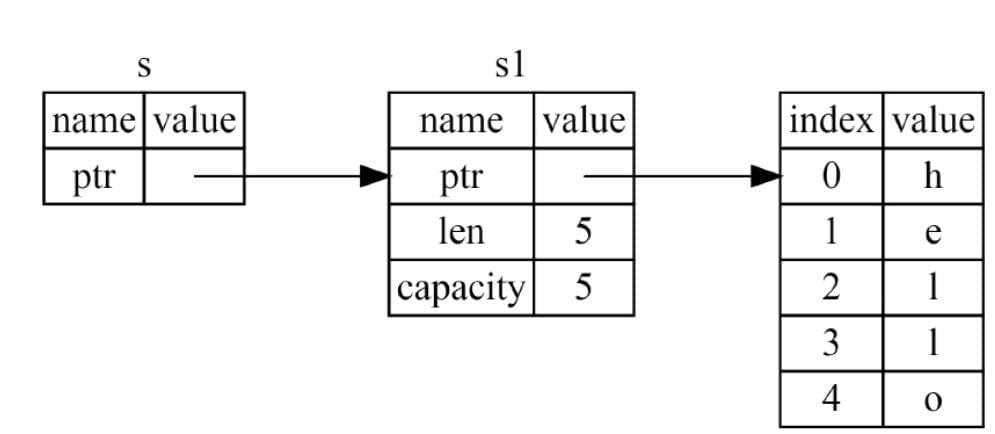
也就是说,什么也不拷贝,但是多了个新的指针,指向原变量,值的所有权还是在s1上,并且引用不会持有所有权,所以当 s 离开了作用域,它的值也不会被回收。
在 Rust 里,这种通过引用传递给函数参数的方法,称为借用,也就是你用完了别人的东西,要原封不动的还给人家。没错,原封不动,这又是和其他语言不太一样的地方。
1 | fn main() { |
让我们把 s1 修改为可变,然后通过引用传给 s ,试图修改一下值,不出意外,编译器报错!引用是不可变的。
但其实很多时候,我们确实需要在函数里修改变量,怎么办?
所以又有了可变引用
可变引用
定义
1 | fn main() { |
&mut 就是可变引用的关键字,这里我们把参数定义为了可变引入,传入的时候也改成了可变引用,代码就合法了。但 Rust 怎么可能让你这么自由的写代码?这不安全!所以可变引用有非常大的限制。那就是可变引用只能一次声明一个!
1 | fn main() { |
不出意外,这段代码必然报错。
可变引用与数据竞争
这么做的主要原因是让我们在编译的时候避免数据竞争,当指令在满足以下三种情况的时候,就会有数据竞争的情况:
- 两个或两个以上的指针同时访问一片空间
- 其中至少有一个,要往空间写入数据
- 而且又没有同步数据访问的机制
看了以上三种情况应该也能大概直到数据竞争是什么了,大概就是,写和读同步进行,可能导致另一个指针读到的数据不太对,导致你完全无法察觉的bug。
这种情况在 Rust 完全不会出现。因为可能产生数据竞争的代码编译这一关就通过不了哈哈哈。(同理,以上代码如果你不使用 s2, s3 的话其实不会报错,因为你定义了两个,但都没有使用,自然也没有数据竞争,只会有警告,告诉你定义了两个没用的变量)
基于这个理由,我们也可以知道,同时存在不可变引用+可变引用也是不合法的,因为一个只读,一个可能写,也会有数据竞争。而同时存在多个不可变引用的话,就没问题,因为它们都是只读,并不会修改数据。
悬垂引用
在别的语言里,有一个概念叫 悬垂指针,也就是说,一个指针指着块内存,但是内存被释放掉了,指针还指着这块内存,就叫悬垂。在 Rust 里,同样有一套规则确保引用不会进入悬垂状态,具体做法就是,确保引用的内存不会在引用离开自己的作用域时就被释放掉。也就是说,编译器保证引用在作用域内持续有效
先来创建一个悬垂引用
1 | fn main() { |
这里面我们返回了一个引用,但是引用的数据是 s 里的,s 在离开了函数后就会被销毁,引用自然也就悬垂了。
这时候编译会报错:expected named lifetime parameter
报错涉及到了我们之前说的两大最难学的核心概念之一,生命周期,这个会在后面学,现在不管。我们只要直到,Rust 又一次成功的通过报错拦截了我们的危险代码。
所以我们需要及时的去规范我们的代码,避免危险,这里也很简单,我们不返回引用,而是创建一个字符串变量,返回它的所有权就行了。
到这里,引用就讲完了,展开下一个概念,切片。(小声逼逼,这章好长,一边看书,一边写代码,一边写博客,看了我一下午了,没办法还是想一章一章的完整看完)
切片
之前说过,引用没有所有权,但没有所有权的类型还有一个,那就是——切片。用过 python 的应该很清楚这个概念。
切片在 Rust 的本质就是引用几何里一段连续的元素序列。
书里举了一个例子说明切片的好处。
假设我们需要获取一个句子里面某个单词,怎么获取?最简单的方法的方法就是找到第一个单词的索引,知道单词的长度,这样就能随时的通过下标的方式访问到单词。
但这种设计方式有一个问题,那就是单词的索引,它的意义是和单词严格绑定的,当我的句子都已经被销毁的时候,其实索引也就没有了意义,但这时候我们可能用了一个变量来存这个索引,这个变量又不随着句子而销毁,这样就造成了一些冗余的问题,就连 Rust 的编译器也没办法给你挑出毛病来(你也有今天)。
所以就有了切片,我们一次性切出来一块引用,引用这个单词相关的所有字符,当原来的句子没有用了之后,引用也自然会被销毁(没被销毁的情况编译器就报错了)
1 | fn main() { |
使用方法也很简单,在 python 里是冒号,这里就是两个点,也同样是左闭右开,但是注意要写引用。
语法糖也和 python 一样,如果你想从一开始就切,也可以不写第一个数字,如果你想切到最后,也可以不写最后一个数字,例如:
1 | fn main() { |
另外,有趣的是,之前不是说编译器会保证引用持续有效吗?那我在引用离开作用域前手动销毁会怎样?
1 | fn main() { |
当然,肯定会报错。但它的解决方法比较有趣,之前说过,当你定义了不可变引用的时候,就没办法定义可变引用了对吧。而clear本质也是个函数,它清空 s 的内存的话,本质上是需要修改 s 的内容,所以它需要传入一个 s 的可变引用,来对齐进行清空,但我们之前还定义了不可变引用,不可变引用还没进行使用呢,你就没有办法定义可变引用去clear了。没错,根本上还是解决数据竞争的问题,清空本质上是一个写操作,我还要读呢,你就不能写!
当然,同样的,如果你不用读,它就不会报错了,例如:
1 | fn main() { |
书上还提到了其他类型,例如数组也可以切片,此乃废话,不多说。
好勒,第4章到这里就终于结束了,这一章实在太长了,毕竟涉及到核心概念,看了我半天时间,今天就差不多到这吧。
- 标题: 【Rust学习记录】4. 所有权
- 作者: TwoSix
- 创建于 : 2023-03-26 20:18:45
- 更新于 : 2024-07-04 23:52:28
- 链接: https://twosix.page/2023/03/26/【Rust学习记录】4-所有权/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。